My name is Ali Ghafelebashi. I am a final year Ph.D. candidate in Industrial and Systems Engineering at the University of Southern California (USC). I have also earned a Master's degree in Computer Science from USC. I am honored to have Professor
Meisam Razaviyayn as my Ph.D. advisor.
I work at the intersection of optimization, machine learning, and transportation where I design scalable and distributed optimization models and build private machine learning models for transportation applications.
Machine Learning & Data Science Intern, Shipt
June 2023-August 2023
• Achieved 6% shopper acquisition cost reduction by developing an optimization model (ILP) (OR-Tools, PuLP, SQL)
• Improved shopper retention prediction accuracy by 3% by utilizing LightGBM and including more features
Data Science (Full Stack) Intern, Shipt
May 2022-August 2022
• Enhanced statistical power of delivery bundling experiment by 7% by providing a simulation-based power estimation package (SQL, pandas, NumPy)
• Increased speed of treatment group selection by 12X by designing optimization-based (MIQP) package (CVXPY, Git)
Research Assistant, University of Southern California
August 2018-Present
Projects:
With rapid population growth and urban development, traffic congestion has become an inescapable issue, especially in large cities. Many congestion reduction strategies have been proposed in the past, ranging from roadway extension to transportation demand management. In particular, congestion pricing schemes have been used as negative reinforcements for traffic control. In this paper, we study an alternative approach of offering positive incentives to drivers to take different routes. More specifically, we propose an algorithm to reduce traffic congestion and improve routing efficiency via offering (personalized) incentives to drivers. We propose to exploit the wide accessibility of smart devices to communicate with drivers and develop an incentive offering mechanism using individuals’ preferences and aggregate traffic information. The incentives are offered after solving a large-scale optimization problem in order to minimize the total travel time (or minimize any cost function of the network such as total carbon emission). Since this massive-size optimization problem needs to be solved continually in the network, we developed a distributed computational approach. The proposed distributed algorithm is guaranteed to converge under a mild set of assumptions that are verified with real data. We evaluated the performance of our algorithm using traffic data from the Los Angeles area. Our experiments show congestion reduction of up to 5% in arterial roads and highways.
We study federated learning (FL) with non-convex loss functions and data from people who do not trust the server or other silos. In this setting, each silo (e.g., hospital) must protect the privacy of each person’s medical record), even if the server or other silos act as adversarial eavesdroppers. To that end, we consider inter-silo record-level (ISRL) differential privacy (DP), which requires silo i’s communications to satisfy record/item-level DP. We propose novel ISRL-DP algorithms for FL with heterogeneous (non-i.i.d.) silo data and two classes of Lipschitz continuous loss functions: First, we consider losses satisfying the Proximal Polyak-Lojasiewicz (PL) inequality, which is an extension of the classical PL condition to the constrained setting. In contrast to our result, prior works only considered unconstrained private optimization with Lipschitz PL loss, which rules out most interesting PL losses such as strongly convex problems and linear/logistic regression. Our algorithms nearly attain the optimal strongly convex, homogeneous (i.i.d.) rate for ISRL-DP FL without assuming convexity or i.i.d. data. Second, we give the first private algorithms for non-convex non-smooth loss functions. Our utility bounds even improve on the state-of-the-art bounds for smooth losses. We complement our upper bounds with lower bounds. Additionally, we provide shuffle DP (SDP) algorithms that improve over the state-of-the-art central DP algorithms under more practical trust assumptions. Numerical experiments show that our algorithm has better accuracy than baselines for most privacy levels.
Traffic congestion has become an inevitable challenge in large cities due to population increases and expansion of urban areas. Various approaches are introduced to mitigate traffic issues, encompassing from expanding the road infrastructure to employing demand management. Congestion pricing and incentive schemes are extensively studied for traffic control in traditional networks where each driver is a network "player". In this setup, drivers' "selfish" behavior hinders the network from reaching a socially optimal state. In future mobility services, on the other hand, a large portion of drivers/vehicles may be controlled by a small number of companies/organizations. In such a system, offering incentives to organizations can potentially be much more effective in reducing traffic congestion rather than offering incentives directly to drivers. This paper studies the problem of offering incentives to organizations to change the behavior of their individual drivers (or individuals relying on the organization's services). We developed a model where incentives are offered to each organization based on the aggregated travel time loss across all drivers in that organization. Such an incentive offering mechanism requires solving a large-scale optimization problem to minimize the system-level travel time. We propose an efficient algorithm for solving this optimization problem. Numerous experiments on Los Angeles County traffic data reveal the ability of our method to reduce system-level travel time by up to 6.9%. Moreover, our experiments demonstrate that incentivizing organizations can be up to 8 times more efficient than incentivizing individual drivers in terms of incentivization monetary cost.
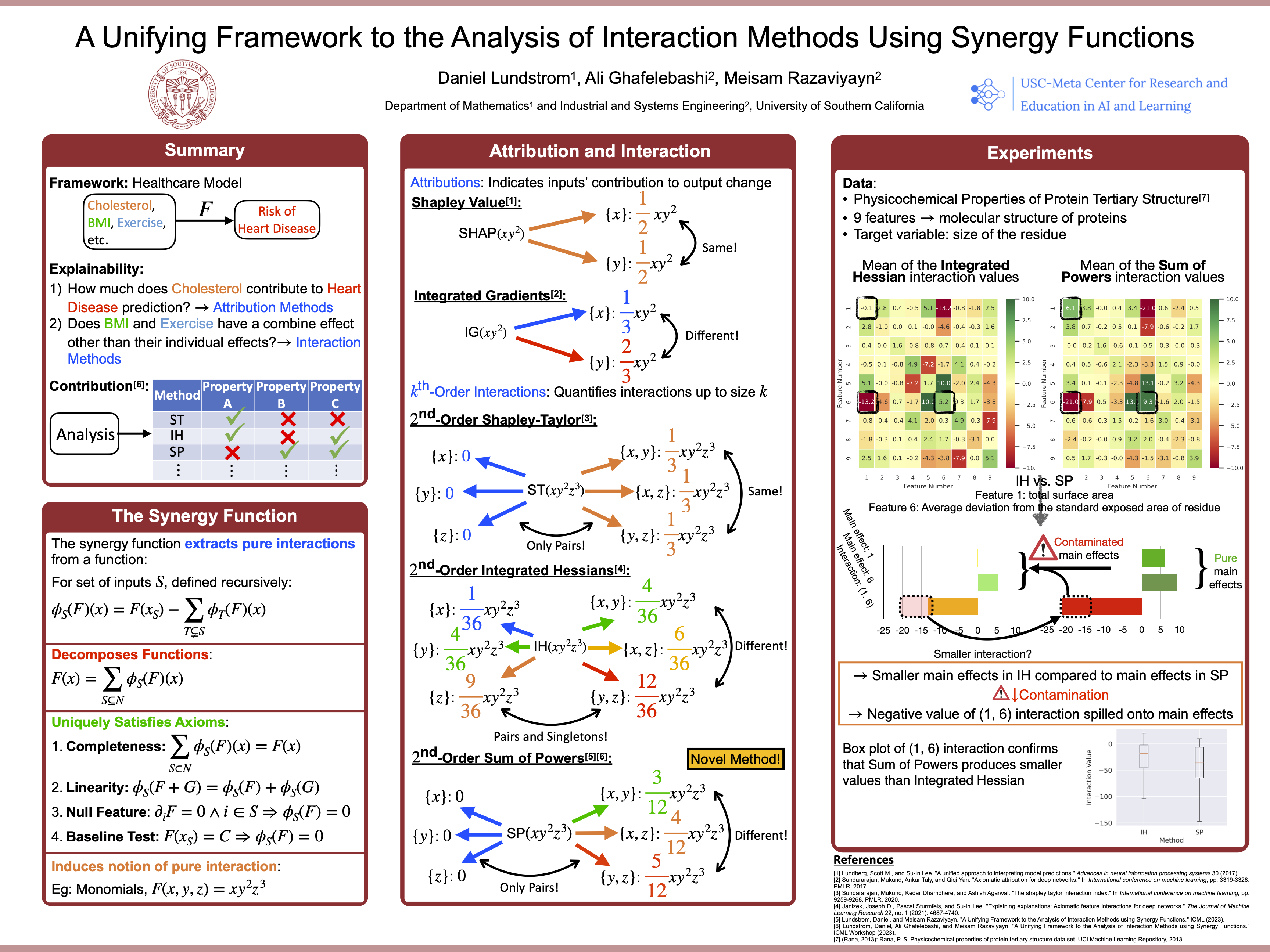
Deep learning is expected to revolutionize many sciences and particularly healthcare and medicine. However, deep neural networks are generally “black box,” which limits their applicability to mission-critical applications in health. Explaining such models would improve transparency and trust in AI-powered decision making and is necessary for understanding other practical needs such as robustness and fairness. A popular means of enhancing model transparency is to quantify how individual inputs contribute to model outputs (called attributions) and the magnitude of interactions between groups of inputs. A growing number of these methods import concepts and results from game theory to produce attributions and interactions. This work presents a unifying framework for game-theory-inspired attribution and k^th-order interaction methods. We show that, given modest assumptions, a unique full account of interactions between features, called synergies, is possible in the continuous input setting. We identify how various methods are characterized by their policy of distributing synergies. We establish that gradient-based methods are characterized by their actions on monomials, a type of synergy function, and introduce unique gradient-based methods. We show that the combination of various criteria uniquely defines the attribution/interaction methods. Thus, the community needs to identify goals and contexts when developing and employing attribution and interaction methods. Finally, experiments with Physicochemical Properties of Protein Tertiary Structure data indicate that the proposed method has favorable performance against the state-of-the-art approach.
Mixed linear regression (MLR) model is among the most exemplary statistical tools for modeling non-linear distributions using a mixture of linear models. When the additive noise in MLR model is Gaussian, Expectation-Maximization (EM) algorithm is a widely-used algorithm for maximum likelihood estimation of MLR parameters. However, when noise is non-Gaussian, the steps of EM algorithm may not have closed-form update rules, which makes EM algorithm impractical. In this work, we study the maximum likelihood estimation of the parameters of MLR model when the additive noise has non-Gaussian distribution. In particular, we consider the case that noise has Laplacian distribution and we first show that unlike the the Gaussian case, the resulting sub-problems of EM algorithm in this case does not have closed-form update rule, thus preventing us from using EM in this case. To overcome this issue, we propose a new algorithm based on combining the alternating direction method of multipliers (ADMM) with EM algorithm idea. Our numerical experiments show that our method outperforms the EM algorithm in statistical accuracy and computational time in non-Gaussian noise case.
• Ranked 1 for a four-year sequence in Department of Industrial Engineering at Amirkabir University of Technology, 2015-2018
• Ph.D. fellowship by the University of Southern California Viterbi School of Engineering, 2018
• M.Sc. fellowship by Sharif University of Technology, 2018
• M.Sc. fellowship by Amirkabir University of Technology, 2018
Selected Courses
• CSCI 570: Analysis of Algorithms
• ISE 633: Large Scale Optimization and Machine Learning
• CSCI 567: Machine Learning
• CSCI 566: Deep Learning and Its Applications
• CSCI 561: Artificial Intelligence
• ISE 632: Network Flows and Combinatorial Optimization
• CSCI 585: Database Systems
• CSCI 572: Information Retrieval and Web Search Engines
Volunteering
Mentorship
June 2023-August 2023
• Mentoring Vikram Meyer in the USC Viterbi Summer Undergraduate Research Experience (SURE) program. SURE is an 8-week summer residential research program at the University of Southern California in Los Angeles. The program provides undergraduate students with the opportunity to work on cutting-edge research projects with academic-industry collaboration under the mentorship of Viterbi faculty and PhD students.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}